
You're probably familiar with horizontally scaling stateless applications. Most likely running containerized microservices under the hood, powered by a database engine, and serving traffic through a load balancer. A fairly standard recipe for scale, right?
A Short Story
You're working for a successful SaaS business with a superb product offering - customers are queuing around the block to use your services. Your product is great, you have a scalable architecture, the sales team is full of closers, and you have a strong, committed engineering team to grow the offering - you're on to a winner!

Time goes by. With your trusty architecture by your side you're scaling smoothly and without any real issues - you're serving more customers than ever. The infrastructure tackles a growing customer base each day - it doesn't even break a sweat!
But then one day while minding your own business (working on the next killer feature) you see metrics on your dashboards starting to tickle amber territory. Then a buzz. A rapid incrementing of the number of emails in your inbox. PagerDuty has broken down your "Do Not Disturb" setting.
Confusion ensues. You hurriedly jump onto the infrastructure, load the dashboards, and you see your database engine in the red zone! It's reaching its capacity, and the headroom is shrinking very fast.
Terraform? Where we're going, we don't need Terraform.
ClickOps to the rescue.
You've upscaled the server several times already and you take a decision to spin up another server and move half of the data over to spread the load.
The dashboards promptly return to green, PagerDuty calms down - you've saved the day!
You wipe the sweat off your brow, lower your shoulders from your ears, and relax in your chair. You mull over the issue in your mind, but quickly brush this off as just one of those days - the issue was rather simple at heart, you think, more resources were required to deal with the load, that's all. All is well again - fire has been put out - you are a hero.

In the corner of your eye, you notice that the database servers begin to struggle again. Huh!? You repeat the exercise and shard the databases across more servers, and the problem goes away.
...how strange...this came a lot faster than you expected...
Harmony returns.
The next morning you open your laptop ready for another routine software release. You build new images, roll them into production, perform your verification checks, and consider the job done.
But just a few hours later as users begin to use the new features, you spot a random web server biting the dust, in a flash of red on the dashboard. Must be a coincidence! A few seconds later, you see another server also meet its fate - how bizarre! In a few short minutes all web servers are dead, while new servers valiantly charge forth into the vanguard to absorb fresh waves of users - only to perish in an even shorter time frame - it's a bloodbath!
The dashboards have been flooded with crimson - like the Overlook hotel's faulty lift - sites are inaccessible, and all customers have just suffered a huge outage.
All hands are on deck to understand what happened and you decide to revert the release, which mercifully resolves the issue. No one quite understands the root cause. The engineers put a hold on their current work to deep dive into the logs, access patterns, and see if they can spot anything. After a little digging, they strike gold!
There was an issue in the new release only triggered by a specific series of actions, which kills the process, and by extension the web server - the patch is easy, and the new version no longer brings production to its knees. The junior engineers breath a sigh of release. The seniors continue to look worried - how did such an issue cascade across all of production?
In this case the estate fell victim to the so-called "poison pill" scenario, wherein a fault triggered by user behavior brings down one instance, and as the user continues to use the system in the same way (or retrying their actions), it brings down other servers that are now trying to compensate for their out of fallen colleague. The contagion quickly infects each server, until it brings the whole estate down. Nobody is quite sure what made this issue so transmissible.
Before anyone can get to the bottom of it, a few weeks later your application locks up out of the blue! No one can access the site, web boxes are not particularly strained, database servers still have plenty of headroom... How bizarre! You start digging around and notice you can't connect to SQL Server at all, but the underlying server itself is responding and working well. You dig deeper and find that SQL connection limits have been exceeded when traffic reached its peak.
Little did you know, that you've introduced a new source of problems with the new database server topology, that simply didn't exist before. Lesson learned the hard way!

Your architecture has become a bit of a whale by now, with hundreds of instances being balanced very carefully as you serve hundreds of millions of requests. All of these servers, serving traffic in a round-robin fashion, randomly establishing connections to all the different SQL boxes, quickly reach the connection limit, preventing any new connections from being established. Requests awaiting new connections block the server request queues which quickly become saturated and bring down the service due to a self-inflicted denial of service.
Things are not looking good. You run some scripts to kill SQL connections, and you reduce the connection pool lifetime in the application along with the max pool size to restore service and bring the application back to life.
Time to rethink things, and accept things for what they are - the architecture has become the problem and is no longer suitable. As with grief, in production engineering, the first step is acceptance: Murphy's law always applies.
Your enormous business success has taken you on a wild journey that has left you with a behemoth of an infrastructure to manage where each day can bring around new challenges (which may be exhilarating for the problem-solvers inside of us), as each day of growth, brings you into the unknown, uncharted territory.
Things that have performed well in the past start to struggle, assumptions which held true before are no longer valid, lessons are learned the hard way, issues and outages become more frequent, and you come to the realization that you must make some fundamental changes.
You begin a new journey of research to discover what could be done to increase fault tolerance, isolation, and return the service back to life, and healthy operating norms.
Enter Cell-Based Architecture
We are a very successful, and rapidly growing organization, and this constantly pushes us to get better, to change things, and improve. As our infrastructure started to outgrow itself and become a challenge to manage, we started to look to new approaches, and learn from the best to move to a true, global scale application, and remove scaling limitations that may have existed with the prior approach. As a wise man once said, at scale, everything fails all the time - there is no getting around that and you must accept it, and build your application accordingly, to minimize the blast radius, increase fault tolerance, and focus on improved recovery and reliability. These became our guiding principles in selecting a new architecture.
Our research has taken us to Cell-Based Architecture, which has been well adopted by AWS for planet-scale, resilient services. The premise is simple, and rooted in Biological systems, to provide a natural way to grow, and become resilient to failures via isolation.
Here are some fantastic resources we have found in our research.
Physalia: Cell-based Architecture to Provide Higher Availability on Amazon EBS - presented by Werner Vogels - AWS CTO
AWS - How to scale beyond limits with cell-based architectures
AWS Aurora also relies on cell-based architecture https://www.allthingsdistributed.com/2019/03/amazon-aurora-design-cloud-native-relational-database.html
AWS Whitepaper on Reducing Blast Radius with Cell-Based Architectures
A large ecosystem becomes a bit like a whale, it's very large, not very agile, hard to handle, and if something starts going wrong, you've got a huge problem.

A cell-based architecture is more akin to a pod of well-behaved dolphins - life is easier, and when you do have issues, they're on a much smaller scale, and easier to manage. Things are generally much easier to manage.

Benefits
There are so many benefits to running a cell-based architecture (or a similar setup.)
If you do it right, all cells are always dealing with a deterministic amount of load, which can be planned for, stress-tested, and you can train for real-life activities, as everything becomes very deterministic and manageable.
Health thresholds and load thresholds can be well defined, which in turn will guide your judgment in creating new pods. You're no longer venturing into the unknown each time you add more customers to the environment.
You get a huge benefit from fault isolation - poison pill scenarios can't take down your whole infrastructure. In the worst case, only a single cell is affected, and if that cell is small enough, this should be a small fraction of your overall traffic. The noisy neighbor impact is also greatly diminished.
If the cells are small and manageable (if not, you probably want to subdivide further), you can spin up new ones quite quickly in case you need to scale.
Scaling the capacity (eg. web servers) within an individual cell also becomes much less time-sensitive. eg. In a "whale" type infrastructure, if the servers take 5 mins to become operational from starting scaling, to serving traffic, after a certain point, auto-scaling will not be able to keep up with the speed of incoming traffic, and its growth gradient. If this happens in an individual cell, it's usually a fraction of the growth and impact, but that 5 mins for a server to come online, is still the same - so the time to scale remains the same, but the demand and impact are greatly reduced, and well in control.
Releases can be rolled out, cell-by-cell, rather than all at once to reduce risk and isolate any faults. You may say, Dan, but we use Rolling Updates, so surely that's okay - it's certainly better, but you are still changing the central environment, so there is always a risk associated with it, doing rolling updates, with cell-by-cell updates, takes it to another level.
If you need to roll back an individual cell, it's much faster than the whole environment. Just make sure you have proper verification checks in place, and you know what healthy (and conversely, unhealthy), looks like.
It also seems to be a fairly limitless way to scale things (at least for now) - if it works for AWS at their scale, it'll likely be fine for us for a very long time.
I personally find it quite fascinating that some of the most revolutionary approaches such as these are rooted in biological systems. Nature is amazing!
How we did it?
Our approach to moving the whole infrastructure to cell-based was quite interesting and carried out over a few days.
It was purely an infrastructure undertaking and required no code changes. No need to move frameworks, languages, or move everything to microservices. We kept our joyful monolith as is, and approached it as a logistics challenge.
Once all the research, planning, and testing, were concluded, we were ready to take it to production.
Day 1
First, we created an inventory of all the CNAME records we manage for our customer sites and grouped them by the destination load balancer (we manage lots of them, as AWS only supports 25 SSL certs per load balancer.)
Once we knew that, we looked at which SQL Servers, each customer was hosted on.
We then decided that each SQL Server will become the heart of each cell, and will have its own server fleet, and everything else it needs to function (creating an isolated vertical slice through our architecture.)
This is what we were going for at a very high level - the cell you belong to was dictated by the SQL fleet you were hosted on, and CNAME your site was pointed at (both need to match up.)
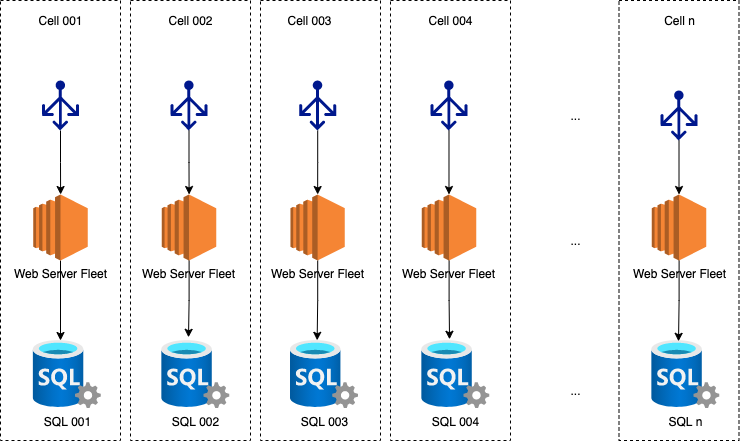
Each cell would be small, and well within the healthy operating parameters.
To split up all of our sites, and load, across the cells, we needed to define some target metrics for each cell - healthy operating parameters. We already know what a healthy latency, error rates, etc. look like from the years of data we monitored in our production environment.
It came down to a few simple calculations to get us started:
- A maximum number of customers hosted per cell - we don't want an excessive number of databases per cell.
- Maximum total number of daily requests a cell should cater for - we knew how many requests were made per site, and how many each web server can cater for, and how quickly requests must ramp up to outrun the web instance warm-up time.
We came up with 2 well-defined numbers (which we continuously tune as we learn more about our architecture.) These formed our upper limits per cell, which we considered healthy.
We ran through some basic maths based on these 2 figures, and came up with the number of cells we need - and inflated it by 10-20% for additional headroom.
We started to set up the underlying infrastructure for these cells, alongside the existing architecture.
A few hours later, once everything was set up, we started to move the first sites (sandbox sites) to the cells, to build confidence and iron out potential issues (can't be too careful.)
The process was simple, mirror the database and files to the new cell fleet, and remap the CNAME (short TTL) to complete the move.
Everything went great.
We continued with several dozen more sites, and then wrapped up for the day.
Day 2
Day 2 was focused primarily on mirroring data, moving sites and associated SSL certs, and remapping CNAMEs. The team was divided into 3 squads, split by responsibility:
- taking backups, and mirroring data to destination cells
- ensuring certs were correctly installed and making CNAME changes
- verifying sites to ensure all was moved correctly
By the end of day 2, we moved over 80% of our EU estate to a cell-based architecture, without any issues.
Day 3-5
These days were focused on finalizing the EU re-architecture, and applying the same methodology to US architecture.
The original infrastructure was left intact (although, drastically scaled-down in terms of capacity) until all the migrations were completed.
Upon successful completion of all EU and US moves, the original "whale" style infrastructure was deprecated and torn down.
New Challenges
Whilst the new architecture brings a LOT of great benefits, it does introduce new challenges that are worth considering.
We had to adjust our reporting pipelines as we now had lots of 'mini' deployments, instead of a few 'large' ones. Ensuring configuration consistency, data ingestion consistency, alarming, and adjusting the dashboards to reflect this took a bit of effort and planning - this was largely a one-off effort. We still discover better ways of doing things, but that's a part of the learning journey.
The release process needed to be adjusted to cater for deployments to individual cells, and doing it cell-by-cell, rather than all cells at once.
We came up with the health targets/target upper limits for cells, which were focused around 2 main figures - number of sites, and the total number of requests served per cell. Over time, the usage patterns change as customers grow and scale or their engagement improves as a result of our strategic help and services. This means that starting metrics for each cell, slowly drift and change over time.
This required some new dashboards and pipelines to be built, to keep track of these metrics, and prompt us when changes need to happen - rebalancing the cell, to ensure we fit within the upper limits.
Results
Overall, the journey was really worthwhile, and we found a lot of benefits we didn't anticipate from this move.
- We noticed the overall latency metrics (average, p75, p95, and p99) were on average 35% lower on each cell. This was mainly attributed to less horizontal hopping and trying to serve so many databases per cell.
- Transient error rates dropped by over 50% - whilst low prior to the move, errors related to networking or other transient issues were reduced by 50%.
- Adhoc spikes in traffic due to large organized events are handled much better within each cell due to better overall headroom, and less noisy neighbor impact.
- The frequency of issues related to latencies, error rates, or other similar issues, has been dramatically reduced.
There is still a lot to learn and optimize, but our experience with the cell-based architecture so far has been excellent!

