
Amazon S3 was a game-changer when it came to the market. Incredible durability and availability, very high performance, ease of use, cheap and completely serverless (scale as you need, and only pay for what you use.)
You create a bucket, upload your files, and then serve them from the bucket. You could run static websites, stream videos, or use it as a backend storage provider for your applications (most common use.) Extremely versatile.
It comes built-in with:
- encryption
- version control
- replication
- auditability
- logging
- security
- policy management
- access management
- easy-to-use web-based portal
However, like any solution/technology, and it comes with its share of problems and vulnerabilities. It's not a carefree silver bullet.
A well-known practice is to lock down your buckets, and for your IAM credentials to (hopefully) align with least privilege principles. Great! But what if your files can be funnelled to another account without your knowledge, or if files can be positioned on your domain, regardless of how much you lock down your buckets?
We'll cover some of the least known, and more dangerous attack vectors for S3:
- bucket parking, and
- subdomain takeover
Bucket Parking
As many of us know, the S3 bucket names are unique at a global level, not at the account level. This means that it is technically a shared space, and collisions may happen.
Now let's think about the implications of that fact...
Bucket parking attacks take advantage of that fact, and collisions are sought out on purpose.
Imagine hosting a SaaS application, which supports uploading business-critical documents via your interface, to an S3 bucket, where each of your customers gets their own bucket, with a unique name (eg. a combination of their business name, and a pre/post-fix of some sort.)
Example
Your customer, "Dunder Mifflin" have an isolated bucket, auto-created by your software, and named as follows.
dunder-mifflin-docs
Anytime they upload a document, it gets safely put into the dunder-mifflin-docs bucket using your AWS Credentials.
The bucket is securely locked down from public access, has restrictive access policies in place, and your AWS Credentials are also heavily locked down to prevent their use for unauthorized activities, aside from a select few actions on the S3 service (such as PutObject.)
If any new customer, joins, your code auto-creates buckets for them, and names it accordingly to that naming format, and the same rigorous lock-down is applied to the bucket.
All good so far, right?
Not really - this is where things get dangerous due to the shared space nature of S3.
How do you know that this bucket in fact belongs to you when uploading files, and is not just another bucket in the globally shared namespace of AWS S3 that happens to have this name?
If it's a globally shared name space, any existing bucket with that name, could belong to someone else. In a normal scenario, this is fine, as you'd notice the collision, and get AccessDenied when trying to upload to this bucket (it's likely locked down, and you don't have access.)
Let's return to our example, and let's assume you just signed a new customer, "Vance Refrigeration".
Your code will attempt to create a bucket if one doesn't exist. However, if an attacker already created a bucket called:
vance-refrigeration-docs
and applied a very open access policy to the bucket, your code will be told the bucket exists and will be able to successfully upload documents to this bucket, even though it is not yours, and your own setup is locked down.
Intriguing, right?! Regardless of the restrictions, you applied on your own buckets and IAM credentials - as long as you can execute PutObject, you're vulnerable.
Here is a bucket setup, that would allow the attacker to accept files from your application without any restrictions - it just needs to get your application to try and put files into a bucket with that name.
You need Everyone Write access.
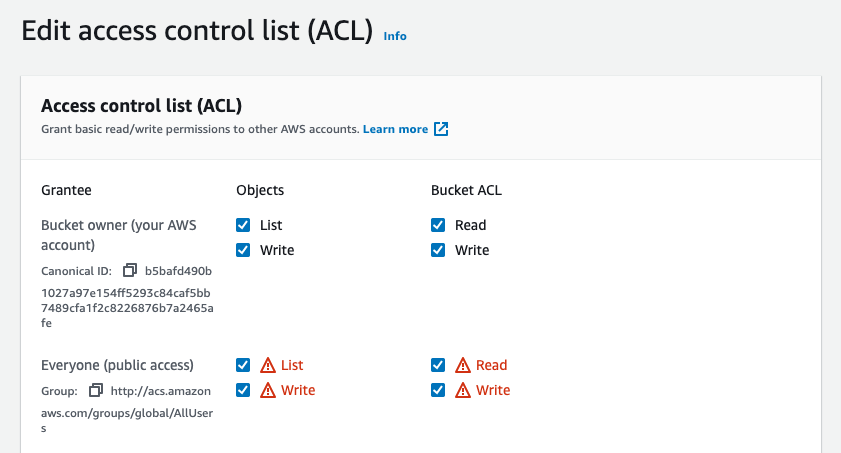
And public access to be disabled.
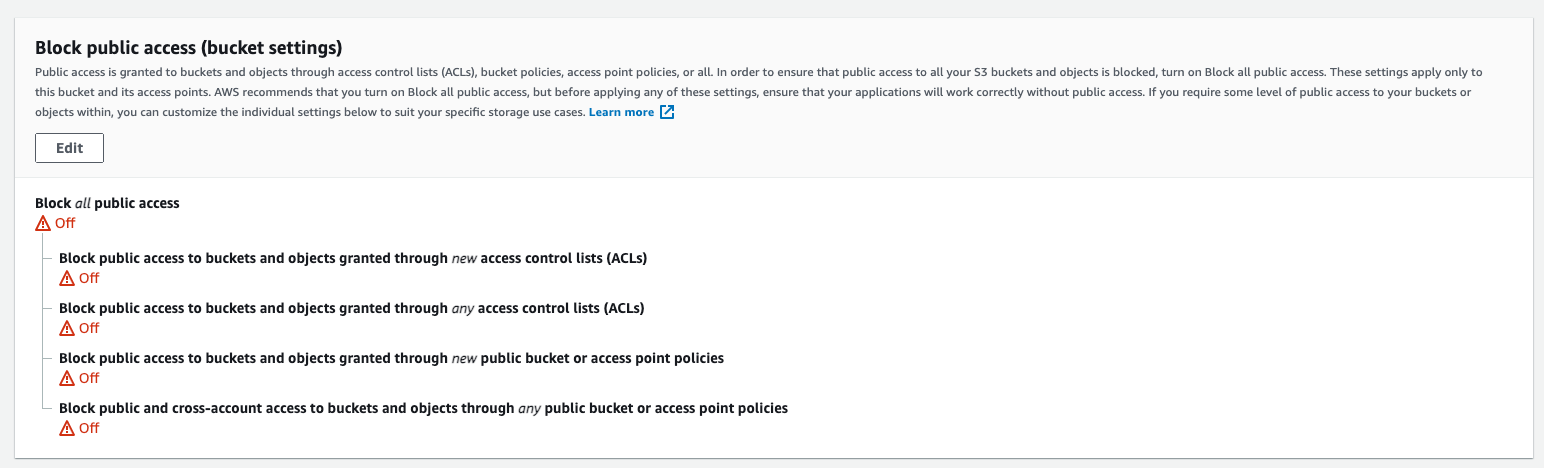
Your code will continue to function (the bucket name it was looking for exists, and accepts its requests) and you're none the wiser, but now your and your customer's data lives in someone else's account.
This is what the exploit looks like at a high level.
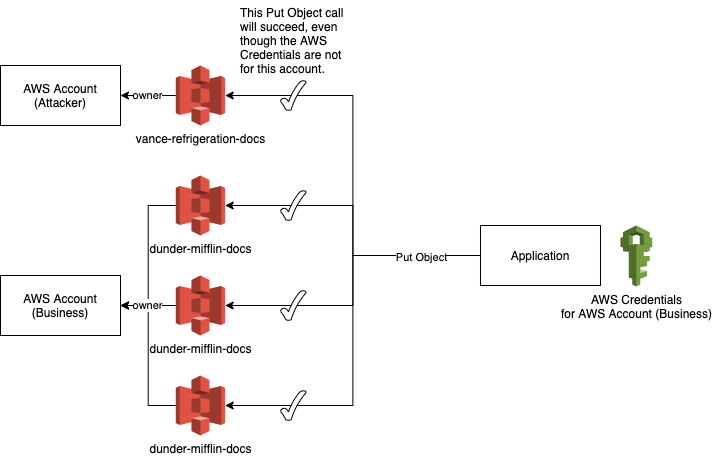
This of course relies on knowing the bucket naming format, which is generally not known, but can be extracted in many different ways, and should be generally considered a non-secret. If your security relies on bucket names being un-guessable or unknown, your mitigation is weak.
We have been successful in replicating this behaviour in our experiment labs, and regardless of the level of lockdown in the intended destination account, the files were funnelled out successfully.
Solution
AWS recognized the risk associated with this and provided an easy way to guard your code against it.
The main problem is that the code/client assumes that the bucket is in the intended destination account, but it is never made explicit - remember, we're operating in a shared namespace, not in an isolated space in your AWS Account.
In September 2020, the following announcement was made, about the support of bucket ownership verification headers, which can provide constraints on uploading files.

| Access method | Parameter for non-copy operations | Copy operation source parameter | Copy operation destination parameter |
|---|---|---|---|
| AWS CLI | --expected-bucket-owner | --expected-source-bucket-owner | --expected-bucket-owner |
| Amazon S3 REST APIs | x-amz-expected-bucket-owner header | x-amz-source-expected-bucket-owner header | x-amz-expected-bucket-owner header |
A previously successful call, to PutObject directed at an open bucket owned by the attacker, would now fail, and return AccessDenied, because AWS will verify the bucket owner to the supplied Header value for us.
You're using Zero Trust principles, to verify if your requests should in fact proceed, based on constraints you impose on the request itself.
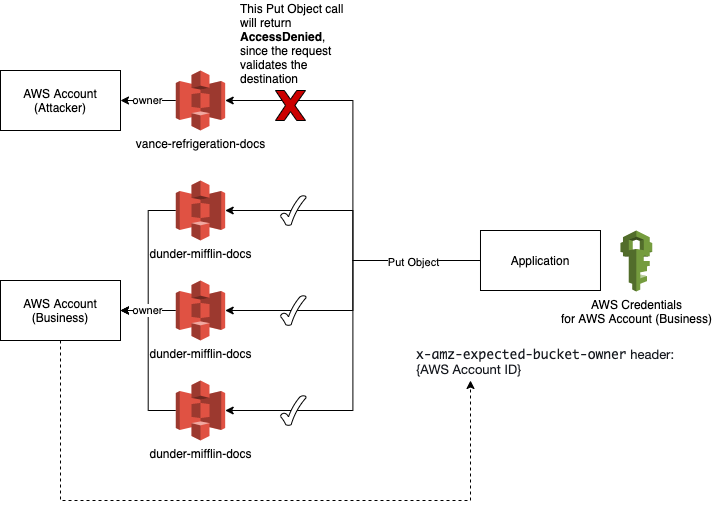
This secures your application from being exploited with this attack vector, by embracing Zero Trust principles and forcing the requests to validate the destination, instead of assuming that the bucket is always safe to write to as long as you have the permission to do so.
Disclaimer: At the point of writing this, a lot of open-source S3 Storage Adapters, and Providers for various systems, don't implement the Expected Bucket Owner functionality, and can therefore be vulnerable to the above exploits.
Subdomain Takeover
This is a similar type of attack, where the attacker creates buckets with very specific names, to perform attacks on otherwise trusted sites. This attack is largely opportunistic in nature and relies on misconfigurations to be present.
Imagine you have a site that users S3 static hosting, to load your assets. Now imagine, you have several of these. Each S3 bucket has a CNAME, allowing it to be served on your trusted domain.
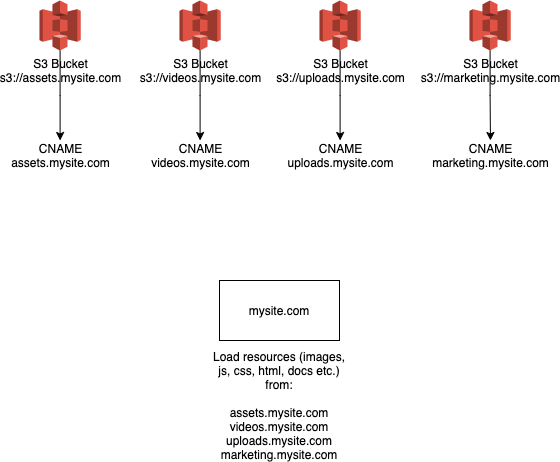
Sometime in the future, you delete a bucket but forget to clean up the CNAME.
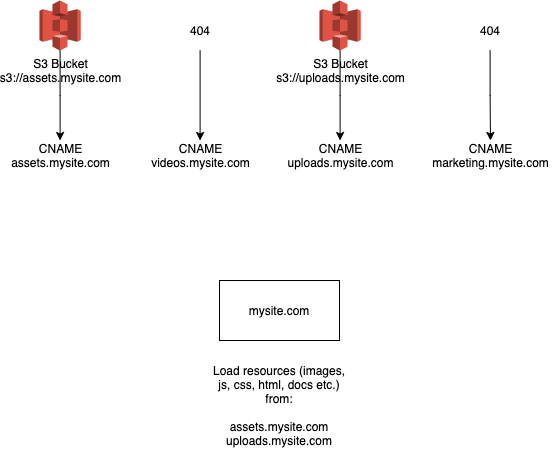
Since S3 bucket names are shared, upon deletion, the name gets released into the wild.
Now, an attacker could simply take that bucket name, create their own bucket in the same region, and put malicious files which are now part of your "trusted site/domain".
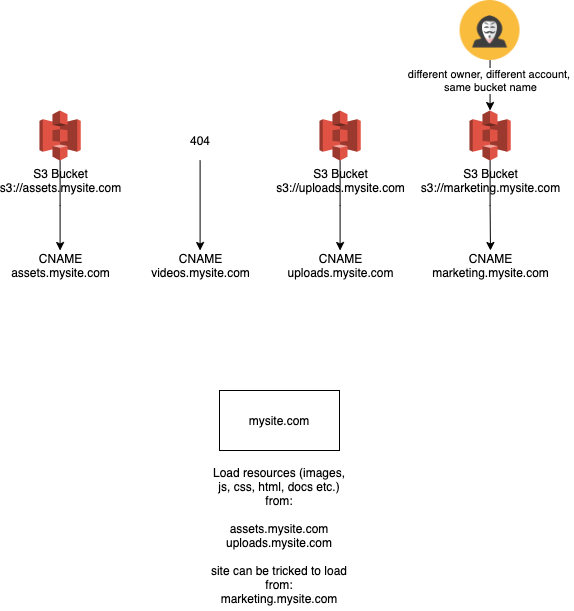
This can be utilized for:
- XSS
- Phishing
- Bypassing domain security
- Stealing sensitive user data, cookies, etc.
For example, the US Department of Defence suffered from this vulnerability.

Solution
First and foremost, make sure you have a good S3 bucket housekeeping process, and ensure that your buckets are accounted for.
Keep an inventory of any buckets which have CNAMEs pointing at them - if you're gathering this information retrospectively, look for buckets that have Static Website Hosting enabled in the first instance.
Audit your DNS entries, and ensure you don't have any DNS CNAME entries pointing at non-existent (or, not owned) S3 buckets.
This can be done in an automated fashion, by using the Route53 APIs to load all Hosted Zone records, and compare to the S3 buckets in your account, and flag any which don't align.
It comes down to having strong change management in place for your assets, and DNS-hosted zones (usually a forgotten or poorly controlled part of the infrastructure.)
Verification of any change is a must:
- verification to ensure correct decommissioning
- verification to ensure the correctness of changes
- verification to ensure the correctness of an implementation
- etc.
Code reviews and Pull Requests are similarly used to verify someone's work and changes.
Infrastructure processes and changes should undergo the same level of scrutiny (zero trust principle), as you'll find mistakes and opportunities for improvement, and eliminate a huge source of entropy, which may lead to security vulnerabilities.
Conclusion
Zero Trust Engineering principles can bring a lot of security benefits across the board, as demonstrated by the S3 examples above.
With the Bucker Parking example, AWS thankfully provides a simple way to verify the bucket owner to prevent accidental file funnelling to external accounts.
With Subdomain takeover, a stronger process and housekeeping are required to ensure things are kept in order. Zero Trust principles are a great start to this, simply adding a deliberate verification step following any changes, will go a long way.
